A highly advanced content analysis and text-mining software with unmatched handling and analysis capabilities,
WordStat is a flexible and easy-to-use text analysis software – whether you need text mining tools for fast extraction of themes and trends, or careful and precise measurement with state-of-the-art quantitative content analysis tools.
WordStat gives you unprecedented flexibility for analyzing text and relating its content to structured information, including numerical and categorical data, due to seamless integration with
SimStat – Provalis Research’s statistical data analysis tool
QDA Miner – Provalis Research’s qualitative data analysis software
Stata – the comprehensive statistical software from StataCorp
WordStat can be used by anyone who needs to quickly extract and analyze information from large amounts of documents. Our content analysis and text mining software is used for:
• Content analysis of open-ended responses, interview or focus group transcripts • Business intelligence and competitive websites analysis • Information extraction and knowledge discovery from incident reports, customer complaints • Content analysis of news coverage or scientific literature • Automatic tagging and classification of documents • Fraud detection, authorship attribution, patent analysis • Taxonomy development and validation
WordStat is capable of reading and processing numerous different languages. It includes various dictionaries including Australian, Catalan, Dutch, English, German and Indonesian to name a few.
KEY AND UNIQUE FEATURES
Import Word, Excel, HTML, SPSS, Stata, NVivo or PDFs. Connect and directly import from social media, emails, web survey platforms, and reference management tools.
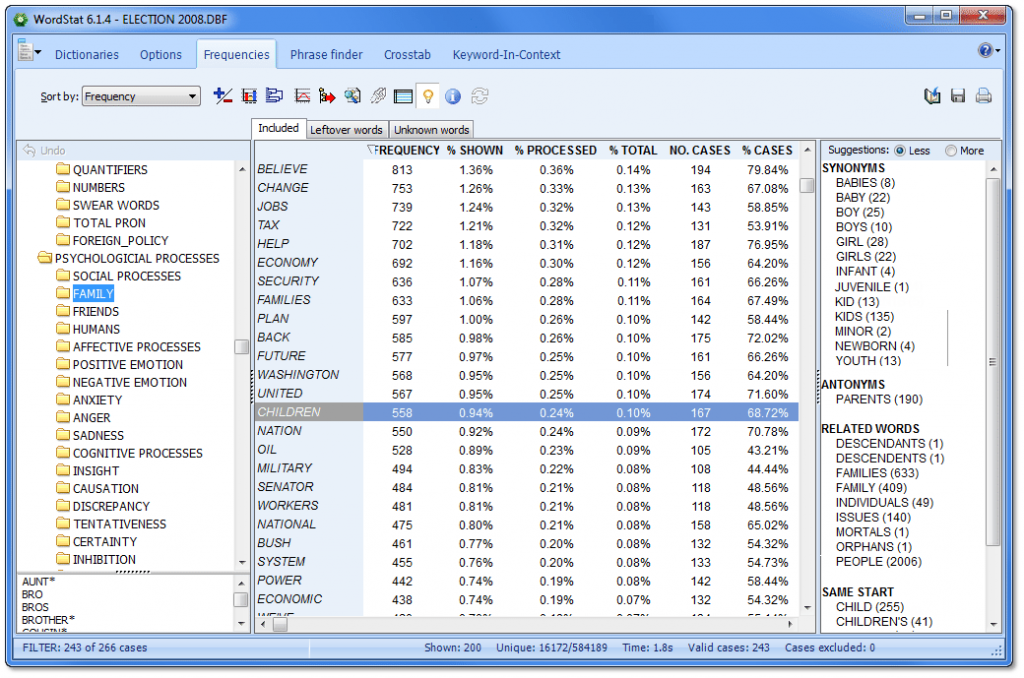
Powerful content analysis and text mining software for handling large amounts of unstructured information. WordStat can process up to 20 million words per minute and identify all references to user-defined concepts using categorization dictionaries.
Integrated exploratory text mining and visualization tools such as clustering, multidimensional scaling, proximity plots, and more, to quickly extract themes and automatically identify patterns.
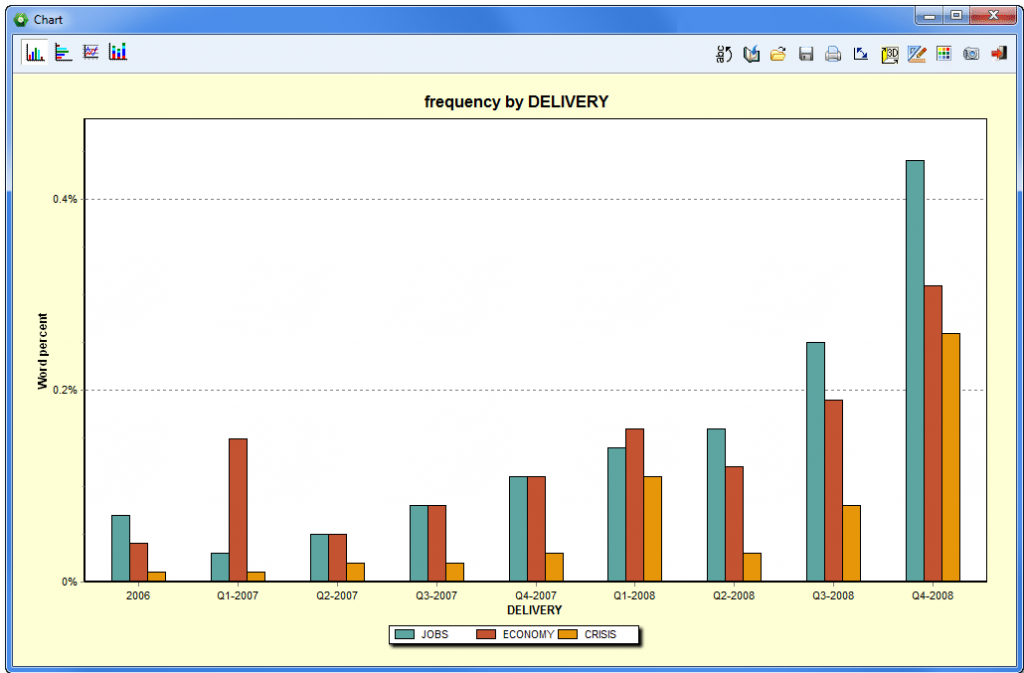
Relates unstructured text with structured data such as dates, numbers or categorical data for identifying temporal trends or differences between subgroups or for assessing relationship with ratings or other kinds of categorical or numerical data.
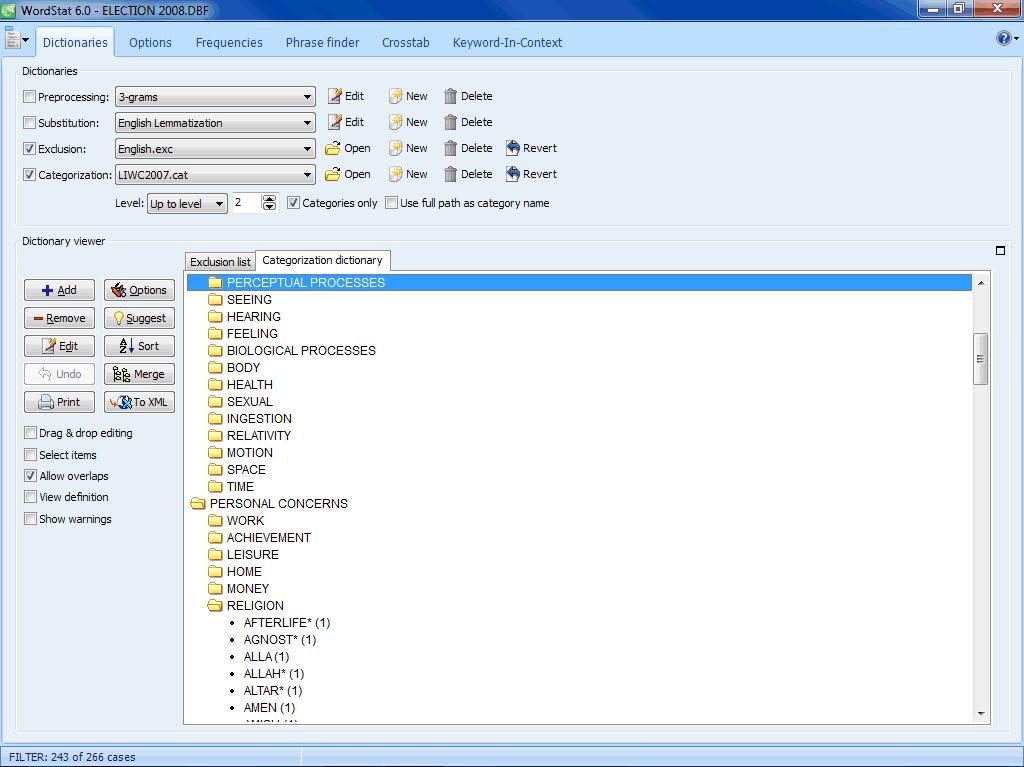
Use existing or create your own hierarchical content analysis dictionaries or taxonomies composed of words, word patterns, phrases as well as proximity rules (such as NEAR, AFTER, BEFORE) for achieving precise measurement of concepts.
Truly unique computer assistance for dictionary building with tools for extracting common phrases and technical terms and for quickly identifying in your text collection, misspellings, synonyms, antonyms and related words.
One click access to keyword-in-context and keyword retrieval tools for easy identification and coding of relevant text segments, validation of content analysis dictionaries, word-sense disambiguation or for drilling down to the source documents.
Seamless integration with a state of the art qualitative coding tool (QDA Miner), allows more precise exploration of data or more in-depth analysis of specific documents or extracted text segments when needed.
Machine Learning for automatic document classification using Naive Bayes and K-Nearest Neighbours algorithms with automatic features selection and validation tools. Classification models may then be saved on disk and reapplied on new data.
Easy importation of databases, spreadsheets and documents (including PDF and HTML) as well as exportation of text analysis results to common industry file formats (Excel, SPSS, ASCII, HTML, XML, MS Word) and graphs (PNG, BMP and JPEG).
WordStat for Stata
WordStat for Stata was created to allow Stata 13 and Stata 15 users running under Windows, to apply text analytics techniques on any string variables stored in a Stata data file.
WordStat combines natural language processing, content analysis and statistical techniques to quickly extract topics, patterns and relationships in large amount of text. It can process millions of words in seconds and compare extracted themes across any other numerical, categorical or date variables in the Stata file.
For a more detailed description of WordStat for Stata features, click here.
For more information or to buy this product please contact us.
For more information on Provalis Research products select a link below or view the brochure.